
지난 1부에서 AWS Kiro에 대한 소개를 마치고, 이번에는 본격적인 실사용기를 들고 왔습니다.
최근 한 달간 Kiro와 함께한 세 가지 프로젝트 중 첫 번째로, 웹 크롤링 어플리케이션 개발 경험을 공유해보려고 합니다.
번역 프로젝트 비용 99.7% 절감... 이정도면 공짜네요!
몇 십만원을 몇 분 만에 날린 뼈아픈 경험담부터 토큰 최적화 꿀팁까지... 진짜 현실적인 이야기들 가득 담았으니 끝까지 읽어보세요!
특정 웹사이트에서 구조화된 정보를 체계적으로 수집할 필요가 생겼습니다.
해당 사이트는 카테고리별로 정리된 콘텐츠 목록이 있고, 각 항목마다 상세 페이지가 따로 구성되어 있는 형태였어요.
1. 게시판 목록 조회
↓
2. 게시판 내 모든 페이지를 돌면서 특정 컬럼 키워드 매칭
↓
3. 매칭된 페이지들을 CSV로 리스트업
↓
4. CSV 기반으로 웹 크롤링 → JSON 변환
↓
5. 영어 텍스트를 한글로 번역하여 새 파일에 append
"어떻게 보면 단순한 작업인데 뭐가 어렵겠어?"
라고 생각했는데... 역시 한방에 되진 않더라구요.


작업 시작
처음에는 그냥 "이런 게 있으니 만들어봐!"라고 대충 던져줬더니...
Kiro가 페이지는 가져오긴 했는데 자기 맘대로 필드를 봐버리니 제대로 된 값을 필터할 수 없더라구요.
❌ 처음 시도:
사용자: "게시판에서 특정 키워드 찾아서 가져와"
Kiro: "네! 이 필드가 중요해 보이네요!" (엉뚱한 곳 크롤링)
"아... AI라고 해서 다 알아서 해주는 건 아니구나."
그래서 리스트 페이지 소스를 copy한 뒤 Kiro에게 샘플을 제공하고 어느 자리를 가져와야 하는지 명확히 명령했습니다.
✅ 개선된 방법:
사용자: "이 HTML 샘플을 보고, 정확히 이 위치의 데이터를 가져와"
Kiro: "알겠습니다! 지정된 위치에서 데이터를 추출하겠습니다."
그제서야 정상적으로 움직이더군요!
당연히 상세페이지도 동일하게 샘플을 제공해야 했습니다.
번역의 필요성
하지만 문제가 하나 있었어요.
보는 사람이 한국사람이었으니 당연히 데이터를 제공하려면 영어 텍스트를 한글로 바꾸는 작업을 해야 했는데요.
얼마전에 다른 고객 프로젝트 POC로 하던 Google Translate API 작업하다가 의도치 않은 비용 17만원이 한방에 나간 기억이 나서 좀 불안했어요. 물론 여러 언어를 동시에 번역했어야 하는 작업이었기에 그럴 수도 있겠다 싶긴 했지만 당연히 비용은 중요하니까 신경을 많이 써야 합니다.

Deepl 써볼까?
전 평소에 번역은 DeepL로 많이 활용하고 있다 보니 "DeepL이면 괜찮지 않을까?" 싶었어요.
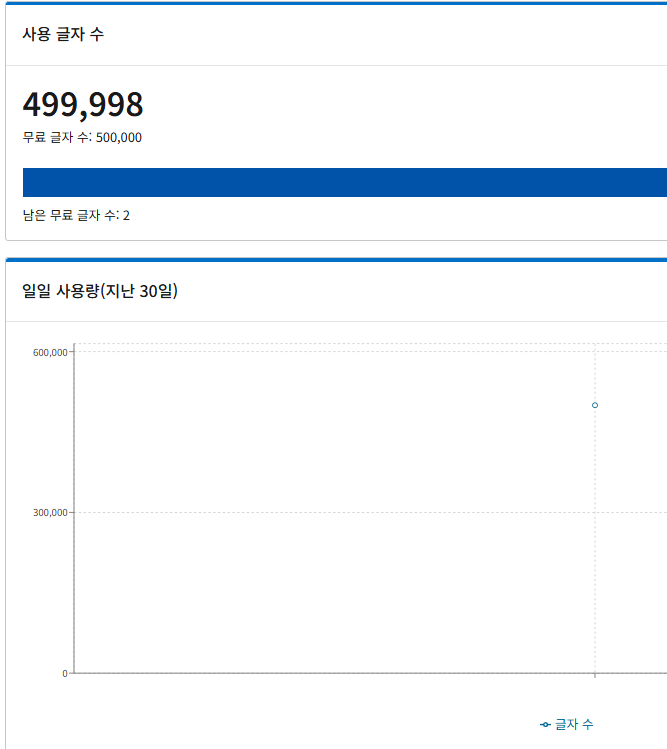
그래서 찾아보니 월 50만자까진 무료더라구요?
혹시나 해서 Kiro한테 번역해야 하는 영어 텍스트 개수를 전체 세어본 다음 50만자가 넘는지 물어봤어요.
그랬더니 50만자까진 아니라서 충분히 free tier로 해결이 가능하다고 이야기하더라구요.
"그래! 알겠어!"
그래서 DeepL용 library를 Python에 넣고 번역을 시작했어요.
그런데...
그런데 막상 번역을 해보니 돌리다가 막히는 거에요.
"어? 왜지?"
하고 보니까 무료량을 넘어서서 안 되는 거더라구요. 50만자를 다 써서 딱 제가 예상한 데이터양에 절반만 딱 해놨더라구요.
Kiro가 50만자 안 된다고 했는데...
LLM 번역으로의 전환

막상 지금 번역 툴을 바꾸면 번역 퀄리티가 바뀔까 봐 고민해보다가...
"LLM으로 하면 어차피 비슷하지 않을까?"
"Kiro로 어차피 하고 있으니 Bedrock으로 Claude에다가 번역하면 되지 않을까?"
그래서 Kiro와 함께 Bedrock 번역 작업을 시작했어요!
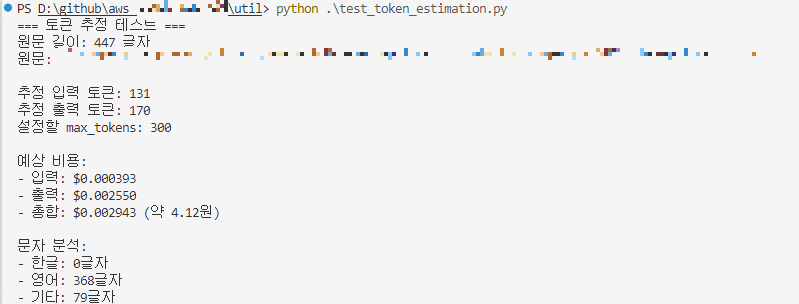
비용에 대한 이슈가 있을 수도 있으니 당연히 토큰 개수를 최대한 줄이는 방향으로 구현했습니다:
- 번역 대상 텍스트 기반으로 실시간 계산
- Bedrock Claude 모델 기반으로 최대 예상 토큰값 계산
- 사용자 approve 후 번역 진행

이렇게 하니까 Google Translate 때처럼 예상치 못한 비용 폭탄을 맞을 위험이 확실히 줄어들더라고요!
번역 결과에 이상한 데이터가?
다 좋은데, 번역하다 보니 "한국어 번역: \n\n" 이런 식의 이상한 텍스트가 달리기 시작하더군요.
원본: "Data Analysis"
번역 결과: "한국어 번역: \n\n데이터 분석"
저도 이건 단건으로 몇번 테스트하다가 알게 되었어요. 혹시나 해서 한번에 돌리지 않고 단건으로 approve하면서 수동으로 검증하는 중이었거든요.
근데 또 이게 매번 나타나는게 아니라 나왔다 안나왔다 하더라구요.
안되겠다... 이건 프롬프트로 강제로 못 넣게 해야겠다 싶었어요.
그래서 다시 Kiro에게 불필요한 텍스트를 제거하고 답변하게 하라고 다시 요청했어요.
"번역 결과만 정확히 출력하고, '한국어 번역:', '번역:', 줄바꿈 등
불필요한 텍스트는 일체 포함하지 말 것"
이렇게 하니 보너스 효과!
결론적으로 이렇게 하니 response하는 토큰값도 줄어들어서 비용도 더 절감되는 효과를 가져왔습니다.
작업 결과물
드디어 작업이 완료되고 비용을 확인해보니...
Claude 4: $0.21
Claude 3.5 (test): $0.08
─────────────────────
총 비용: $0.29 (약 400원)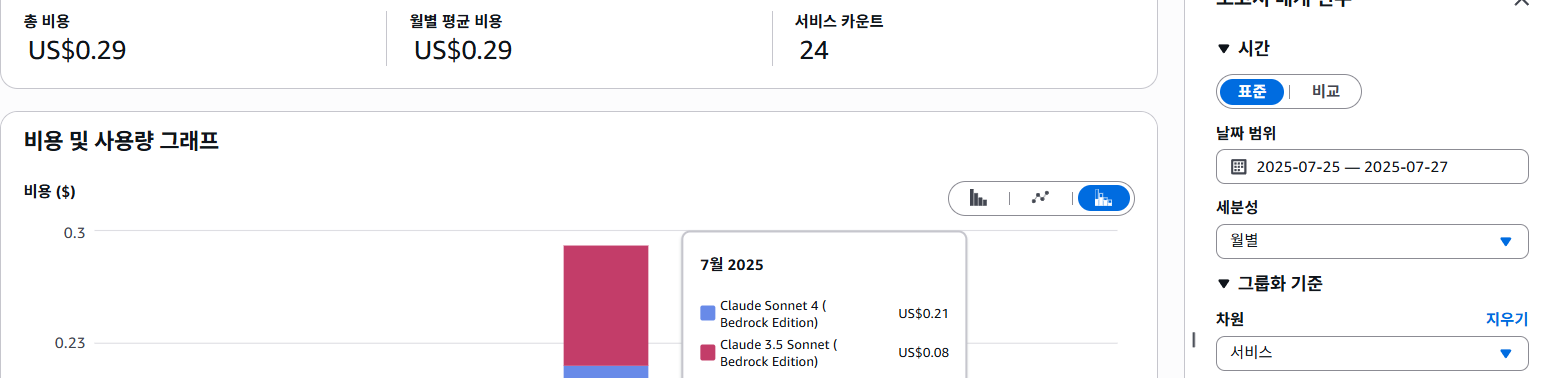
- ⚡ 빠른 응답: 불필요한 토큰 제거로 응답 속도 향상
- 💰 놀라운 비용 절약: 17만원 → 400원 (99.7% 절약!)
- 🎯 정확한 번역: 깔끔한 결과물
- ✨ 데이터 품질: 오염 없는 순수 번역 데이터
다음 번엔 AWS 공부자료 만드는 kiro 프로젝트로 돌아오겠습니다!
그럼 오늘도 즐거운 하루되세요!
'AWS' 카테고리의 다른 글
| AWS Kiro 출시 기념 AI 인터뷰 (0) | 2025.11.18 |
|---|---|
| Amazon Q를 이용한 나만의 개발팀 만들기 (0) | 2025.08.28 |
| AWS Kiro IDE와의 첫 만남: 코딩을 혁신하는 에이전틱 IDE (0) | 2025.07.27 |
| AWS ECS 1-Click Rollback 기능 출시 (0) | 2025.05.26 |
| 시간 관리 앱 사이드 프로젝트 모집공고 (0) | 2025.05.16 |



